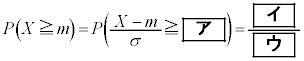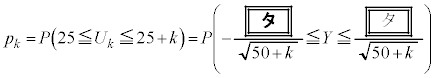�@���ʃe�X�g���wIIB '23�N��3��@
�ȉ��̖�������ɂ������ẮA�K�v�ɉ�����43�y�[�W(���D�{�E�F�u�T�C�g�ł͖�蕶�̖���)�̐��K���z�\��p���Ă��悢�B
(1) ���鐶�Y�n�Ő��Y�����s�[�}���S�̂��W�c�Ƃ��A���̕�W�c�ɂ�����s�[�}��1�̏d��(�P�ʂ�g)��\���m���ϐ���X�Ƃ���Bm��σ�𐳂̎����Ƃ��AX�͐��K���z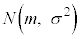 �ɏ]���Ƃ���B
�ɏ]���Ƃ���B
(i) ���̕�W�c����1�̃s�[�}����ׂɒ��o�����Ƃ��A�d����mg�ȏ�ł���m��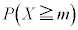 ��
�� �ł���B
(ii) ��W�c���疳��ׂɒ��o���ꂽ�傫��n�̕W�{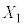 �C
�C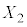 �C����C
�C����C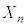 �̕W�{���ς�
�̕W�{���ς�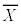 �Ƃ���B
�Ƃ���B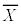 �̕���(���Ғl)�ƕW�����͂��ꂼ��
�̕���(���Ғl)�ƕW�����͂��ꂼ�� 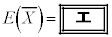 �C
�C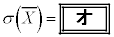
�ƂȂ�B
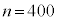 �C�W�{���ς�30.0g�C�W�{�̕W������3.6g�̂Ƃ��Am�̐M���x90���̐M����Ԃ��������j�ŋ��߂悤�B
�C�W�{���ς�30.0g�C�W�{�̕W������3.6g�̂Ƃ��Am�̐M���x90���̐M����Ԃ��������j�ŋ��߂悤�B
�|���j�|�|�|�|�|�|�|�|�|�|�|�|�|Z��W�����K���z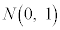 �ɏ]���m���ϐ��Ƃ��āA
�ɏ]���m���ϐ��Ƃ��āA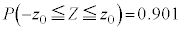 �ƂȂ�
�ƂȂ� �𐳋K���z�\���狁�߂�B����
�𐳋K���z�\���狁�߂�B���� ��p�����m�̐M���x90.1���̐M����Ԃ����߂��邪�A�����M���x90���̐M����ԂƂ݂Ȃ��čl����B
��p�����m�̐M���x90.1���̐M����Ԃ����߂��邪�A�����M���x90���̐M����ԂƂ݂Ȃ��čl����B
�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|���j�ɂ����āA �ł���B
�ł���B
��ʂɁA�W�{�̑傫��n���傫���Ƃ��ɂ́A��W�����̑���ɁA�W�{�̕W������p���Ă悢���Ƃ��m����Ă���B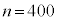 �͏\���ɑ傫���̂ŁA���j�Ɋ�Â��ƁAm�̐M���x90���̐M����Ԃ�
�͏\���ɑ傫���̂ŁA���j�Ɋ�Â��ƁAm�̐M���x90���̐M����Ԃ� �ƂȂ�B
�ƂȂ�B
 �C
�C �̉Q(�������̂��J��Ԃ��I��ł��悢�B)
�̉Q(�������̂��J��Ԃ��I��ł��悢�B) 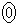 �@σ�@�@
�@σ�@�@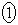 �@
�@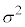 �@�@
�@�@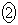 �@
�@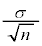 �@�@
�@�@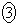 �@
�@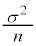
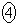 �@m�@�@
�@m�@�@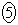 �@
�@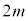 �@�@
�@�@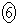 �@
�@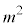 �@�@
�@�@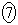 �@
�@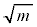
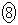 �@
�@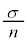 �@�@
�@�@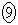 �@
�@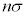 �@�@
�@�@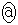 �@
�@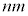 �@�@
�@�@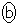 �@
�@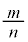
 �ɂ��ẮA�ł��K���Ȃ��̂��A�����`�̂��������I�ׁB
�ɂ��ẮA�ł��K���Ȃ��̂��A�����`�̂��������I�ׁB�@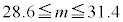 �@�@�@
�@�@�@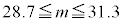 �@�@�@
�@�@�@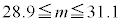
�@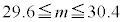 �@�@�@
�@�@�@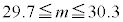 �@�@�@
�@�@�@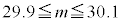
(2) (1)�̊m���ϐ�X�ɂ����āA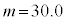 �C
�C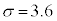 �Ƃ�����W�c���疳��ׂɃs�[�}����1�����o���A�s�[�}��2��1�g�ɂ������̂�܂ɓ���Ă����B���̂悤�ɂ��ăs�[�}��2��1�g�ɂ������̂�25�܍��B���̍ہA1�܂��̏d���̕��U�����������邽�߂ɁA�����s�[�}�����ޖ@���l����B
�Ƃ�����W�c���疳��ׂɃs�[�}����1�����o���A�s�[�}��2��1�g�ɂ������̂�܂ɓ���Ă����B���̂悤�ɂ��ăs�[�}��2��1�g�ɂ������̂�25�܍��B���̍ہA1�܂��̏d���̕��U�����������邽�߂ɁA�����s�[�}�����ޖ@���l����B
�|�s�[�}�����ޖ@�|�|�|�|�|�|�|�|
����ׂɒ��o�����������̃s�[�}���ɂ��āA�d����30.0g�ȉ��̂Ƃ���S�T�C�Y�A30.0g����Ƃ���L�T�C�Y�ƕ��ނ���B�����āA���ނ��ꂽ�s�[�}������S�T�C�Y��L�T�C�Y�̃s�[�}��������I�сA�s�[�}��2��1�g�Ƃ����܂����B
�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|
(i) �s�[�}����ׂ�50���o�����Ƃ��A�s�[�}�����ޖ@��25�܍�邱�Ƃ��ł���m��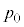 ���l���悤�B����ׂ�1���o�����s�[�}����S�T�C�Y�ł���m����
���l���悤�B����ׂ�1���o�����s�[�}����S�T�C�Y�ł���m���� �ł���B�s�[�}����ׂ�50���o�����Ƃ���S�T�C�Y�̃s�[�}���̌���\���m���ϐ���
�ł���B�s�[�}����ׂ�50���o�����Ƃ���S�T�C�Y�̃s�[�}���̌���\���m���ϐ���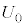 �Ƃ���ƁA
�Ƃ���ƁA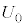 �͓��z
�͓��z �ɏ]���̂�
�ɏ]���̂� �ƂȂ�B
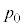 ���v�Z����ƁA
���v�Z����ƁA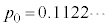 �ƂȂ邱�Ƃ���A�s�[�}����ׂ�50���o�����Ƃ��A25�܍�邱�Ƃ��ł���m����0.11���x�Ƃ킩��B
�ƂȂ邱�Ƃ���A�s�[�}����ׂ�50���o�����Ƃ��A25�܍�邱�Ƃ��ł���m����0.11���x�Ƃ킩��B
(ii) �s�[�}�����ޖ@��25�܍�邱�Ƃ��ł���m����0.95�ȏ�ƂȂ�悤�ȃs�[�}���̌����l���悤�B
k�����R���Ƃ��A�s�[�}����ׂ�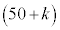 ���o�����Ƃ��AS�T�C�Y�̃s�[�}���̌���\���m���ϐ���
���o�����Ƃ��AS�T�C�Y�̃s�[�}���̌���\���m���ϐ���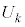 �Ƃ���ƁA
�Ƃ���ƁA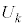 �͓��z
�͓��z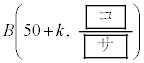 �ɏ]���B
�ɏ]���B
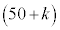 �͏\���ɑ傫���̂ŁA
�͏\���ɑ傫���̂ŁA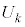 �͋ߎ��I�ɐ��K���z
�͋ߎ��I�ɐ��K���z �ɏ]���A
�ɏ]���A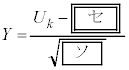 �Ƃ���ƁAY�͋ߎ��I�ɕW�����K���z
�Ƃ���ƁAY�͋ߎ��I�ɕW�����K���z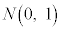 �ɏ]���B
�ɏ]���B
����āA�s�[�}�����ޖ@�ŁA25�܍�邱�Ƃ��ł���m����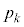 �Ƃ����
�Ƃ���� �ƂȂ�B
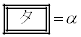 �C
�C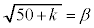 �Ƃ����B
�Ƃ����B
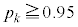 �ɂȂ�悤��
�ɂȂ�悤��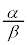 �ɂ��āA���K���z�\����
�ɂ��āA���K���z�\����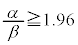 �����悢���Ƃ��킩��B�����ł�
�����悢���Ƃ��킩��B�����ł� 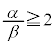 �@����@
�@����@�������R��k���l���邱�ƂƂ���B�@�̗��ӂ͐��ł��邩��A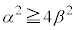 �����ŏ���k��
�����ŏ���k��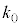 �Ƃ���ƁA
�Ƃ���ƁA �ł��邱�Ƃ��킩��B�������A
�ł��邱�Ƃ��킩��B�������A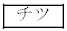 �̌v�Z�ɂ����ẮA
�̌v�Z�ɂ����ẮA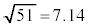 ��p���Ă��悢�B
��p���Ă��悢�B
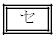
���������āA���Ȃ��Ƃ� �̃s�[�}���𒊏o���Ă����A�s�[�}�����ޖ@��25�܍�邱�Ƃ��ł���m����0.95�ȏ�ƂȂ�B
�̃s�[�}���𒊏o���Ă����A�s�[�}�����ޖ@��25�܍�邱�Ƃ��ł���m����0.95�ȏ�ƂȂ�B
 �`
�` �̉Q(�������̂��J��Ԃ��I��ł��悢�B)
�̉Q(�������̂��J��Ԃ��I��ł��悢�B) �@k�@�@�@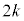 �@�@�@
�@�@�@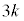 �@�@�@
�@�@�@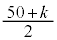
�@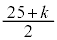 �@�@�@
�@�@�@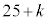 �@�@�@
�@�@�@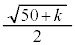 �@�@�@
�@�@�@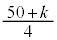
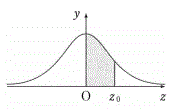
���K���z�\
���̕\�́A�W�����K���z�̕��z�Ȑ��ɂ�����E�}�D�F
�����̖ʐς��܂Ƃ߂����̂ł���B
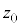 | 0.00 | 0.01 | 0.02 | 0.03 | 0.04 | 0.05 | 0.06 | 0.07 | 0.08 | 0.09 |
| 0.0 | 0.0000 | 0.0040 | 0.0080 | 0.0120 | 0.0160 | 0.0199 | 0.0239 | 0.0279 | 0.0319 | 0.0359 |
| 0.1 | 0.0398 | 0.0438 | 0.0478 | 0.0517 | 0.0557 | 0.0596 | 0.0636 | 0.0675 | 0.0714 | 0.0753 |
| 0.2 | 0.0793 | 0.0832 | 0.0871 | 0.0910 | 0.0948 | 0.0987 | 0.1026 | 0.1064 | 0.1103 | 0.1141 |
| 0.3 | 0.1179 | 0.1217 | 0.1255 | 0.1293 | 0.1331 | 0.1368 | 0.1406 | 0.1443 | 0.1480 | 0.1517 |
| 0.4 | 0.1554 | 0.1591 | 0.1628 | 0.1664 | 0.1700 | 0.1736 | 0.1772 | 0.1808 | 0.1844 | 0.1879 |
| 0.5 | 0.1915 | 0.1950 | 0.1985 | 0.2019 | 0.2054 | 0.2088 | 0.2123 | 0.2157 | 0.2190 | 0.2224 |
| 0.6 | 0.2257 | 0.2291 | 0.2324 | 0.2357 | 0.2389 | 0.2422 | 0.2454 | 0.2486 | 0.2517 | 0.2549 |
| 0.7 | 0.2580 | 0.2611 | 0.2642 | 0.2673 | 0.2704 | 0.2734 | 0.2764 | 0.2794 | 0.2823 | 0.2852 |
| 0.8 | 0.2881 | 0.2910 | 0.2939 | 0.2967 | 0.2995 | 0.3023 | 0.3051 | 0.3078 | 0.3106 | 0.3133 |
| 0.9 | 0.3159 | 0.3186 | 0.3212 | 0.3238 | 0.3264 | 0.3289 | 0.3315 | 0.3340 | 0.3365 | 0.3389 |
| 1.0 | 0.3413 | 0.3438 | 0.3461 | 0.3485 | 0.3508 | 0.3531 | 0.3554 | 0.3577 | 0.3599 | 0.3621 |
| 1.1 | 0.3643 | 0.3665 | 0.3686 | 0.3708 | 0.3729 | 0.3749 | 0.3770 | 0.3790 | 0.3810 | 0.3830 |
| 1.2 | 0.3849 | 0.3869 | 0.3888 | 0.3907 | 0.3925 | 0.3944 | 0.3962 | 0.3980 | 0.3997 | 0.4015 |
| 1.3 | 0.4032 | 0.4049 | 0.4066 | 0.4082 | 0.4099 | 0.4115 | 0.4131 | 0.4147 | 0.4162 | 0.4177 |
| 1.4 | 0.4192 | 0.4207 | 0.4222 | 0.4236 | 0.4251 | 0.4265 | 0.4279 | 0.4292 | 0.4306 | 0.4319 |
| 1.5 | 0.4332 | 0.4345 | 0.4357 | 0.4370 | 0.4382 | 0.4394 | 0.4406 | 0.4418 | 0.4429 | 0.4441 |
| 1.6 | 0.4452 | 0.4463 | 0.4474 | 0.4484 | 0.4495 | 0.4505 | 0.4515 | 0.4525 | 0.4535 | 0.4545 |
| 1.7 | 0.4554 | 0.4564 | 0.4573 | 0.4582 | 0.4591 | 0.4599 | 0.4608 | 0.4616 | 0.4625 | 0.4633 |
| 1.8 | 0.4641 | 0.4649 | 0.4656 | 0.4664 | 0.4671 | 0.4678 | 0.4686 | 0.4693 | 0.4699 | 0.4706 |
| 1.9 | 0.4713 | 0.4719 | 0.4726 | 0.4732 | 0.4738 | 0.4744 | 0.4750 | 0.4756 | 0.4761 | 0.4767 |
| 2.0 | 0.4772 | 0.4778 | 0.4783 | 0.4788 | 0.4793 | 0.4798 | 0.4803 | 0.4808 | 0.4812 | 0.4817 |
| 2.1 | 0.4821 | 0.4826 | 0.4830 | 0.4834 | 0.4838 | 0.4842 | 0.4846 | 0.4850 | 0.4854 | 0.4857 |
| 2.2 | 0.4861 | 0.4864 | 0.4868 | 0.4871 | 0.4875 | 0.4878 | 0.4881 | 0.4884 | 0.4887 | 0.4890 |
| 2.3 | 0.4893 | 0.4896 | 0.4898 | 0.4901 | 0.4904 | 0.4906 | 0.4909 | 0.4911 | 0.4913 | 0.4916 |
| 2.4 | 0.4918 | 0.4920 | 0.4922 | 0.4925 | 0.4927 | 0.4929 | 0.4931 | 0.4932 | 0.4934 | 0.4936 |
| 2.5 | 0.4938 | 0.4940 | 0.4941 | 0.4943 | 0.4945 | 0.4946 | 0.4948 | 0.4949 | 0.4951 | 0.4952 |
| 2.6 | 0.4953 | 0.4955 | 0.4956 | 0.4957 | 0.4959 | 0.4960 | 0.4961 | 0.4962 | 0.4963 | 0.4964 |
| 2.7 | 0.4965 | 0.4966 | 0.4967 | 0.4968 | 0.4969 | 0.4970 | 0.4971 | 0.4972 | 0.4973 | 0.4974 |
| 2.8 | 0.4974 | 0.4975 | 0.4976 | 0.4977 | 0.4977 | 0.4978 | 0.4979 | 0.4979 | 0.4980 | 0.4981 |
| 2.9 | 0.4981 | 0.4982 | 0.4982 | 0.4983 | 0.4984 | 0.4984 | 0.4985 | 0.4985 | 0.4986 | 0.4986 |
| 3.0 | 0.4987 | 0.4987 | 0.4987 | 0.4988 | 0.4988 | 0.4989 | 0.4989 | 0.4989 | 0.4990 | 0.4990 |
�y�L���z��������L���ł��B�����̊F���܂̂��x�������������肽���A��낵�����肢�������܂��B
�y�L���z�L���͂����܂łł��B
���@�{������ǁA���ȏ��ɏ�����Ă��铝�v�Ɋւ����b�������o���Ă��邩�A�����Ō��܂��Ă��܂��܂��B���_�����Ƃ��A��ÑΏ��Ƃ��A�V�C�\��Ƃ��A���v�I��@�Ɋ�Â��K�ȍs�����j�E���f�w�j�͂ǂꂩ�A�ƁA�l��������悤�Ȗ������̂͋��ʃe�X�g�ł͓���̂ł��傤���H
(1)(i) �m���ϐ�X�����K���z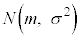 �ɏ]���Ƃ��A���Ғl��m�C�W������σ�ł��B��W�c����s�[�}����1����ׂɒ��o����ƁA�d�������Ғl�ȏ�ɂȂ�m����
�ɏ]���Ƃ��A���Ғl��m�C�W������σ�ł��B��W�c����s�[�}����1����ׂɒ��o����ƁA�d�������Ғl�ȏ�ɂȂ�m����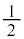 �ł��B�܂��A�m���ϐ�
�ł��B�܂��A�m���ϐ�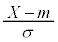 �́A���Ғl0�C�W����1�̕W�����K���z
�́A���Ғl0�C�W����1�̕W�����K���z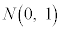 �ɏ]���܂��B�܂�A
�ɏ]���܂��B�܂�A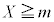 �ƂȂ�m���́A�W�����K���z�ł́A
�ƂȂ�m���́A�W�����K���z�ł́A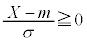 �ƂȂ�m���ɂȂ�܂��B�@�A 0�@�C 1�@�E 2 ......[��]
�ƂȂ�m���ɂȂ�܂��B�@�A 0�@�C 1�@�E 2 ......[��]
(ii) n�̕W�{���W�c���璊�o����Ƃ��A�W�{���ς̊��Ғl��m�C�W�{���ς̕W�����͕�W�c�W������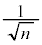 �ł�(��W�c�ƕW�{���Q��)�B
�ł�(��W�c�ƕW�{���Q��)�B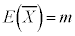 �C
�C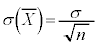 �ł��B�@�G 4�@�I 2 ......[��]
�ł��B�@�G 4�@�I 2 ......[��] ���K���z�\�́A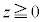 �̕����ɂ��Ă̂ݏ�����Ă���̂ŁA
�̕����ɂ��Ă̂ݏ�����Ă���̂ŁA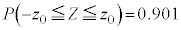 �̂Ƃ��A
�̂Ƃ��A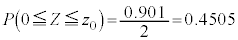 �ƂȂ�Ƃ���𐳋K���z�\����T���܂��B�����Ȃ�̂́A
�ƂȂ�Ƃ���𐳋K���z�\����T���܂��B�����Ȃ�̂́A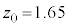 �̂Ƃ��ł��B�@�J 1�@�L�N 65 ......[��]
�̂Ƃ��ł��B�@�J 1�@�L�N 65 ......[��]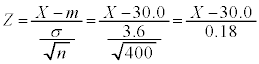 �ɂ��āA
�ɂ��āA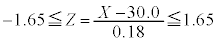 ���A
���A 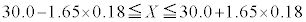 �@��
�@�� 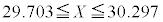
m�̐M���x90�����M������́A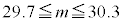 �@�P 4 ......[��]
�@�P 4 ......[��]
(2)(i) ���o�����s�[�}����S�T�C�Y(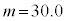 �ȉ�)�ł���m����
�ȉ�)�ł���m����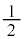 �ł��B�@�R 1�@�T 2 ......[��]
�ł��B�@�R 1�@�T 2 ......[��] �s�[�}����ׂ�50���o�����Ƃ���S�T�C�Y�̃s�[�}���̌���\���m���ϐ���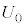 �Ƃ���ƁA
�Ƃ���ƁA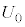 �����z
�����z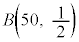 �ɏ]���܂��B�s�[�}�����ޖ@�ŁAS�T�C�Y�AL�T�C�Y1���̑܂�25�܂ł���A�Ƃ������Ƃ́A���o����50�̂���S�T�C�Y��25�Ƃ������ƂŁA���̊m���́A�������s�̌������A
�ɏ]���܂��B�s�[�}�����ޖ@�ŁAS�T�C�Y�AL�T�C�Y1���̑܂�25�܂ł���A�Ƃ������Ƃ́A���o����50�̂���S�T�C�Y��25�Ƃ������ƂŁA���̊m���́A�������s�̌������A 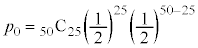 �@�V�X 25 ......[��]
�@�V�X 25 ......[��]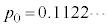 �Ƃ������Ƃ́A�s�[�}����50���o����S�T�C�Y��L�T�C�Y�����傤�ǔ������ɂȂ�\���͂��Ȃ�Ⴂ�A�����Ƃ�������̃s�[�}���𒊏o���Ȃ���S�T�C�Y��25�ɂȂ�Ȃ������m��Ȃ��A�Ƃ������Ƃł��B
�Ƃ������Ƃ́A�s�[�}����50���o����S�T�C�Y��L�T�C�Y�����傤�ǔ������ɂȂ�\���͂��Ȃ�Ⴂ�A�����Ƃ�������̃s�[�}���𒊏o���Ȃ���S�T�C�Y��25�ɂȂ�Ȃ������m��Ȃ��A�Ƃ������Ƃł��B
(ii) ��蕶�̗v���́A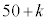 ���o����S�T�C�Y��25�ȏ�A���AL�T�C�Y��25�ȏ����Ƃ��̊m��p���A
���o����S�T�C�Y��25�ȏ�A���AL�T�C�Y��25�ȏ����Ƃ��̊m��p���A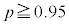 �ƂȂ�k�͂������A�Ƃ������Ƃł��B
�ƂȂ�k�͂������A�Ƃ������Ƃł��B �s�[�}����ׂ�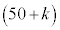 ���o�����Ƃ��AS�T�C�Y�̃s�[�}���̌���\���m���ϐ���
���o�����Ƃ��AS�T�C�Y�̃s�[�}���̌���\���m���ϐ���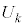 �Ƃ���ƁA
�Ƃ���ƁA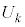 �͓��z
�͓��z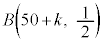 �ɏ]���܂��B
�ɏ]���܂��B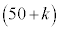 �͏\���ɑ傫���̂ŁA
�͏\���ɑ傫���̂ŁA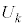 �͋ߎ��I�ɐ��K���z
�͋ߎ��I�ɐ��K���z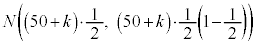 �C�܂�A
�C�܂�A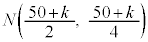 �ɏ]���܂��B�@�Z�@3�@�\ 7 ......[��]
�ɏ]���܂��B�@�Z�@3�@�\ 7 ......[��] ���D1��̎��s�Ŏ���A���N����m��p�C���s��n�Ƃ��āA���z �ł́AA�̋N����̕��ς�
�ł́AA�̋N����̕��ς�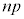 �C���U��
�C���U��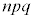 �ƂȂ�܂�(���z���Q��)�B���s��n���[���ɑ傫���Ȃ�ƁA���z�͋ߎ��I�����K���z
�ƂȂ�܂�(���z���Q��)�B���s��n���[���ɑ傫���Ȃ�ƁA���z�͋ߎ��I�����K���z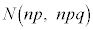 �Ƃ��čl����(
�Ƃ��čl����(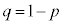 )���Ƃ��ł��܂��B��L�ł́A
)���Ƃ��ł��܂��B��L�ł́A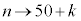 �C
�C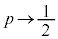 �Ƃ��܂��B
�Ƃ��܂��B 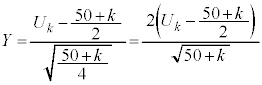 �Ƃ����ƁAY�͋ߎ��I�ɕW�����K���z
�Ƃ����ƁAY�͋ߎ��I�ɕW�����K���z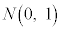 �ɏ]���܂��B
�ɏ]���܂��B
�s�[�}�����ޖ@��25�܍��A�܂�AS�T�C�Y�s�[�}����25�ȏ�(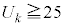 )�A���AL�T�C�Y�s�[�}����25�ȏ�(S�T�C�Y�s�[�}����
)�A���AL�T�C�Y�s�[�}����25�ȏ�(S�T�C�Y�s�[�}����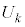 �̂Ƃ��AL�T�C�Y�s�[�}����
�̂Ƃ��AL�T�C�Y�s�[�}����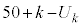 �ł��ꂪ25�ȏ�Ȃ�
�ł��ꂪ25�ȏ�Ȃ�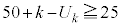 �C�܂�
�C�܂�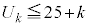 )���o���m��
)���o���m��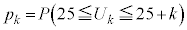 �́A
�́A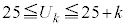 ���A
���A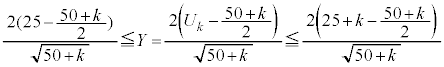 ��
�� 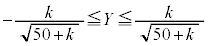
����āA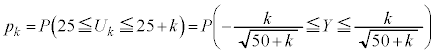 �@�^ 0 ......[��]α�Cβ��p���ď����ƁA
�@�^ 0 ......[��]α�Cβ��p���ď����ƁA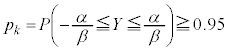
���K���z�\�ŁA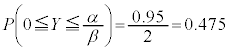 �ƂȂ�Ƃ�
�ƂȂ�Ƃ�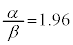 �Ȃ̂ŁA
�Ȃ̂ŁA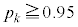 �ɂȂ邽�߂ɂ́A
�ɂȂ邽�߂ɂ́A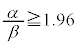 ���
���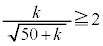 �Ƃ���ƁA
�Ƃ���ƁA 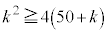 �C
�C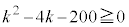
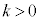 ���A
���A��������ŏ��̎��R��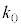 �́A
�́A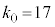 �@�`�c 17 ......[��]����āA���Ȃ��Ƃ�
�@�`�c 17 ......[��]����āA���Ȃ��Ƃ�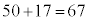 �̃s�[�}���𒊏o����A�s�[�}�����ޖ@��25�܍��m����0.95�ȏ�ɂȂ�܂��B
�̃s�[�}���𒊏o����A�s�[�}�����ޖ@��25�܍��m����0.95�ȏ�ɂȂ�܂��B
�y�L���z��������L���ł��B�����̊F���܂̂��x�������������肽���A��낵�����肢�������܂��B
�y�L���z�L���͂����܂łł��B
�@�@���wTOP�@�@TOP�y�[�W�ɖ߂�
�y�L���z��������L���ł��B�����̊F���܂̂��x�������������肽���A��낵�����肢�������܂��B
�y�L���z�L���͂����܂łł��B
�e���̒��쌠��
�o���w�ɑ����܂��B©2005-2024(�L)����� ��w�y�w�m ���������t���I���n��w�l�b�g�m��w�y�w�m(���ē���������)������́A
�܂��A������܂Ń��[����
�����肭�������B